随着人们对听障人士与常人之间高效交流方法的不断探索,基于深度学习的连续视频手语识别技术作为非常可行的方案,受到了广泛关注。我校计算机学院(软件学院)张怀文研究员团队,针对手语视频模态数据与复杂语言语义难以对齐的问题,通过挖掘手语语言序列中的先验知识,跨模态融合手语视频信息与手语语言知识,有效提升了连续手语视频的表征学习能力。针对连续视频手语识别任务训练时损失函数条件独立的问题,提出了上下文感知的序列转导损失函数,创新地开发了一种条件依赖的连续视频手语识别训练方法。
在跨模态视频表征学习过程中,利用预训练的语言模型提取手语标注语言序列的先验知识,构建语言特征。通过循环多模态上下文融合方法将语言特征与视频特征进行深度结合。文章提出的上下文感知的序列转导损失函数,有效利用已预测序列上下文来指导下一步序列的生成,使得识别过程更加符合实际场景。实验结果表明,这项工作提供了一个有效的基于跨模态上下文序列转导的连续手语识别方法,大幅提升了连续视频手语识别的性能,同时也为手语识别的其他研究工作提供了新的思路。
相关论文被中国计算机学会推荐的A类人工智能国际学术会议 International Conference on Computer Vision(ICCV 2023)录用,题为"C2ST: Cross-modal Contextualized Sequence Transduction for Continuous Sign Language Recognition"。文章作者均来自我校的计算机学院(软件学院),包括:张怀文研究员(第一作者),2022级硕士生郭子航,2021级博士生杨洋,2022级博士生刘鑫,以及呼德研究员(通讯作者)。这项研究得到了国家自然科学基金青年项目、内蒙古大学骏马计划、内蒙古自治区高校青年科技英才等项目的支持。
供稿:计算机学院(软件学院) 编辑:李文娟 审核:王烨辉 刘雪峰
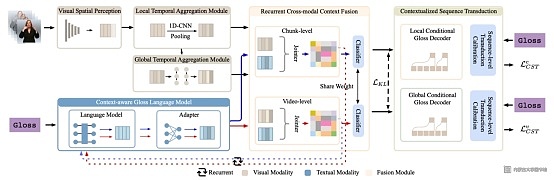
图 1:模型框架图
图 1:模型框架图









