随着大量多模态数据不断被上传到互联网,现有的跨模态检索方法难以适应这种不断增长的数据。最直接的解决方案是基于累积的数据,定期对检索模型进行重新训练或微调。但重新训练和微调模型会导致以前模型提取的特征失去作用,并且重新提取特征会带来巨大的计算开销。我校计算机学院(软件学院)张怀文研究员团队,借鉴人类持续学习的能力,提出了一种在线持续学习的设置以形式化跨模态检索系统面临的数据增长挑战,并基于在线持续学习这一设置创新的开发出一种持续跨模态检索方法。
在持续学习增量数据的过程中,提出跨模态关系一致性方法,通过学习不同会话样本之间的关系,解决在线持续学习中关系偏移的挑战,提出语义表示协调方法,通过吸收跨会话样本知识,缓解跨会话多模态表示语义混淆的挑战。实验结果表明,这项工作提供了一个有效的持续跨模态检索方法,大幅提升了跨模态检索模型应对不断增加的多模态数据时的检索性能,同时也为跨模态检索提供了新的研究方向。
相关论文被中国计算机学会推荐的A类多媒体国际学术会议ACM International Conference on Multimedia(ACM MM 2023)录用,题目为"C2MR: Continual Cross-Modal Retrieval for Streaming Multi-modal Data"。我校计算机学院(软件学院)张怀文研究员为该论文的第一作者,2021级博士生杨洋为第二作者。这项研究得到了国家自然科学基金青年项目、内蒙古大学骏马计划、内蒙古自治区高校青年科技英才等项目的支持。
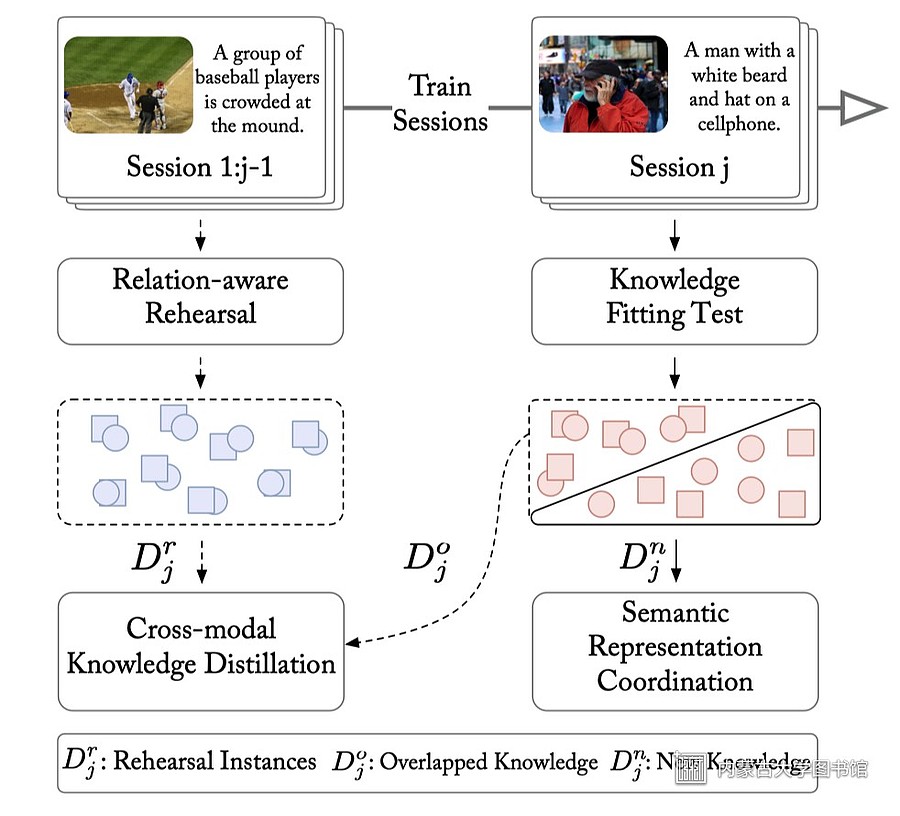
图1:模型框架图
图1:模型框架图









